Arquitetura da Solução¶
A arquitetura da plataforma Gov Hub BR foi elaborada para promover modularidade, escalabilidade e adoção de tecnologias de código aberto, assegurando flexibilidade adaptativa às demandas específicas de diferentes órgãos públicos, sem comprometer os requisitos de governança e qualidade de dados.
Visão Geral¶
O design adota o paradigma Lakehouse, estruturado em três camadas de processamento de dados:
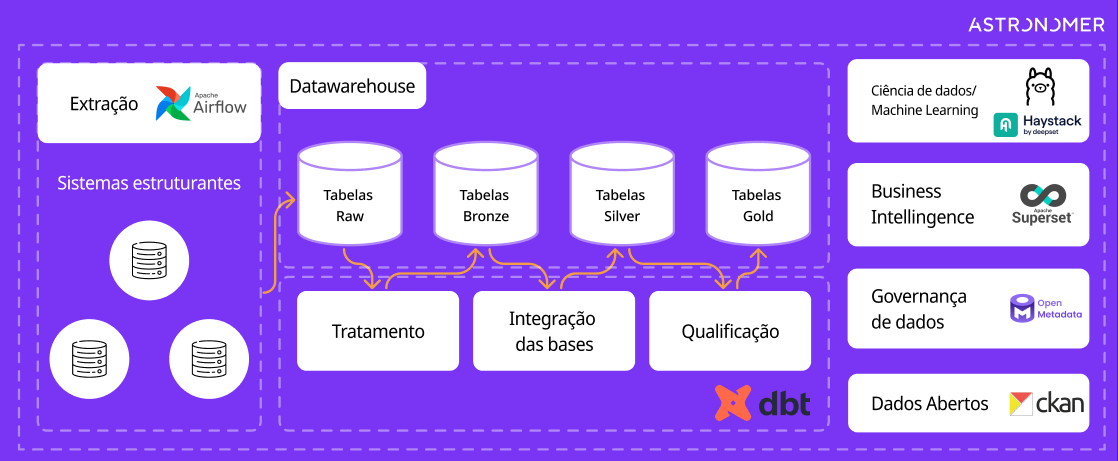
Figura 1: Arquitetura completa da solução Gov Hub BR, demonstrando o fluxo de dados
Fluxo de Processamento de Dados¶
A plataforma Gov Hub BR implementa um pipeline de dados estruturado que opera em ciclos automatizados para garantir a disponibilidade contínua de informações governamentais atualizadas e confiáveis.
Extração e Orquestração: O Apache Airflow executa rotinas diárias de extração de dados, coordenando a coleta automatizada de informações das APIs governamentais através de DAGs (Directed Acyclic Graphs) programadas. Este processo assegura a atualização sistemática da base de dados com as informações mais recentes disponíveis.
Transformação e Qualificação: O DBT (Data Build Tool) processa os dados extraídos aplicando transformações programáticas, validações de qualidade e regras de negócio. A solução adota a arquitetura Medallion com quatro camadas distintas:
- Raw: Preservação integral dos dados originais sem qualquer alteração, mantendo a fidelidade às fontes
- Bronze: Primeira etapa de processamento com limpeza básica e padronização de formatos
- Silver: Dados integrados, normalizados e enriquecidos, prontos para análises exploratórias
- Gold: Camada final com dados agregados e estruturados conforme regras de negócio específicas
Business Intelligence: O Apache Superset consome principalmente as tabelas da camada Gold, garantindo que dashboards e relatórios apresentem informações com máxima qualidade, consistência e performance otimizada para suporte à tomada de decisão estratégica.
Extensões Avançadas: A arquitetura escalável permite a integração de componentes adicionais para casos de uso especializados, incluindo ciência de dados, governança de metadados e transparência pública (conforme detalhado na seção de Funcionalidades Avançadas).
Esta abordagem em camadas proporciona rastreabilidade completa do processo, controle rigoroso de qualidade e escalabilidade para grandes volumes de dados governamentais.
Componentes Principais¶
Apache Airflow¶
Disponibiliza orquestração robusta de fluxos de trabalho (ETL) por meio de Grafos Acíclicos Dirigidos (DAGs), coordenando a extração automatizada de dados brutos a partir das APIs governamentais, com registro de dependências e monitoramento em tempo real.
DBT (Data Build Tool)¶
Responsável pela aplicação de transformações programáticas em SQL, modelagem de dados e geração de artefatos nas camadas Silver e Gold. Facilita versionamento, testes automatizados e documentação contínua dos modelos.
Astronomer Cosmos¶
Extensão que integra nativamente o DBT ao Airflow, habilitando a execução orquestrada de modelos DBT dentro das DAGs e simplificando a gestão de dependências entre tarefas de transformação.
PostgreSQL¶
Data Warehouse centralizado que armazena todas as camadas de dados da arquitetura Medallion. Configurado com otimizações analíticas específicas para:
- Particionamento temporal por data de extração
- Índices otimizados para consultas agregadas
- Isolamento de schemas por camada (raw, bronze, silver, gold)
- Controle de acesso diferenciado por tipo de operação
Apache Superset¶
Ferramenta de business intelligence que consome a camada Gold, permitindo a construção de painéis interativos e relatórios analíticos parametrizáveis, promovendo a disseminação de insights corporativos.
Flexibilidade e Escalabilidade¶
A pilha pode ser executada localmente via Docker Compose para validações iniciais, e dimensionada para ambientes de produção em nuvem, incluindo:
- Execução distribuída do Airflow em Kubernetes ou CeleryExecutor.
- Substituição de PostgreSQL por soluções analíticas escaláveis (Redshift, Snowflake, BigQuery).
- Otimizações de cache e materializações no Superset para grandes volumes de dados.
Funcionalidades avançadas em desenvolvimento¶
A arquitetura escalável do Gov Hub BR foi projetada para suportar componentes adicionais que expandem significativamente as capacidades da plataforma, atendendo a demandas especializadas de análise avançada, governança e transparência:
Ciência de Dados e Machine Learning¶
Tecnologias: Haystack + Ollama
A integração com ferramentas de processamento de linguagem natural e modelos de machine learning permitirá:
- Análise automatizada de documentos governamentais
- Desenvolvimento de modelos preditivos sobre dados públicos
- Automação de classificação e categorização de conteúdo
- Consultas em linguagem natural: Interface conversacional que permite responder perguntas sobre os dados usando mecanismos de RAG (Retrieval-Augmented Generation) e LLM, facilitando o acesso a informações para usuários não técnicos
Governança de Metadados¶
Tecnologia: OpenMetadata
Implementação de um catálogo corporativo de dados que proporcionará:
-
Catalogação automatizada de todos os ativos de dados
-
Linhagem completa dos dados (data lineage)
- Controle de qualidade e profiling automático
- Descoberta de dados e gestão de vocabulários controlados
- Compliance com regulamentações de proteção de dados
Dados Abertos¶
Tecnologia: CKAN (Comprehensive Knowledge Archive Network)
Portal de dados abertos integrado que oferecerá:
- Publicação automatizada de datasets públicos
- Interface de descoberta e download para cidadãos
- APIs padronizadas para acesso programático
- Metadados enriquecidos e documentação automática
- Conformidade com padrões internacionais de dados abertos
Integração Arquitetural¶
Estas funcionalidades se integram naturalmente à arquitetura existente:
-
Consumo das camadas Gold: Todos os componentes avançados acessam dados processados e validados
-
Orquestração centralizada: Airflow coordena também os fluxos de ML e publicação de dados
- Escalabilidade preservada: Mantém-se a capacidade de escalar horizontalmente
- Governança unificada: OpenMetadata cataloga todos os componentes da solução
Nota: Estas funcionalidades estão em fase de planejamento e desenvolvimento, demonstrando a capacidade de evolução da arquitetura conforme as necessidades dos órgãos públicos.
Configuração da infraestrutura¶
Servidores e ambiente¶
- O projeto pode ser executado localmente com docker-compose ou em ambientes cloud.
- Estrutura recomendada:
- Servidor para orquestração (airflow + cosmos)
- Servidor para banco de dados (postgres)
- Servidor para bi (superset)
Permissões e segurança¶
- Acesso ao banco de dados deve ser controlado com usuários distintos para leitura, escrita e administração.
- Airflow deve se conectar ao banco com usuário restrito (ex:
etl_user). - Superset deve se conectar com um usuário apenas-leitura.
- Recomenda-se a utilização de
.envou secrets manager para variáveis sensíveis.
Conectores¶
- Airflow e dbt usam conexões configuráveis por URI.
- Exemplo de conexão airflow → postgres:
- Superset se conecta ao banco via SQLAlchemy URI configurada na interface web.
Escalabilidade¶
O gov hub br foi desenhado para operar com grandes volumes de dados e pode escalar de forma horizontal e modular:
- Airflow pode ser executado com múltiplos workers em um ambiente Kubernetes ou Celery.
- dbt suporta execução paralela e pode ser integrado com cloud warehouses altamente escaláveis.
- postgres pode ser substituído por soluções como redshift, snowflake ou bigquery conforme a demanda.
- dashboards em superset podem ser otimizados com caching e queries materializadas.
Considerações finais¶
A arquitetura modular do gov hub br permite flexibilidade para evoluir conforme as necessidades dos órgãos públicos, mantendo uma base sólida de governança e performance.